
Over the past six months, I conducted a within-subjects study involving 24 software developers to observe their interactions with various LLM-based programming assistants. The developers tackled a range of programming tasks, while I collected data for 16 distinct productivity metrics using an activity tracker, self-assessment surveys, and screen recordings. The results of my study, which are summarized in this series of articles, offer a nuanced perspective on the current state of AI programming assistants and their influence on software developers.
Articles: Part 1 | Part 2 | Part 3
Introduction
Large language models (LLMs) exhibit remarkable capabilities in generating text-based answers to natural language inquiries. When being trained on extensive natural language datasets, they can produce text that is similar to human-written content (Brown et al. 2020). Moreover, when programming repositories are included in the training data, LLMs can develop the ability to generate code (Chen et al. 2021).
This has led to the emergence of novel LLM-based assistants such as GitHub Copilot and ChatGPT, which assist developers by generating tailored explanations, recommendations, and code snippets. The recent surge in interest in these assistants has sparked a discussion about their impact on developers. Key questions that have emerged include: How proficient are LLM-based assistants at generating code? What are their applications in the field of software development? How do they change the role and the workflows of developers?
This article summarizes the results of previous studies in the field of LLM-based programming assistants to give an overview of the current state of AI assistants in software development.
Capabilities of LLMs
Prior literature has mainly focussed on three specific use cases for AI programming assistants by examining their ability to generate code, fix bugs, and test software.
Code Generation: Various studies come to the conclusion that current AI assistants are able to generate useful code snippets and solve common programming problems. Nevertheless, the produced code is far from perfect as LLMs occasionally deviate from the defined goal or include errors in their suggestions. This problem becomes especially prominent when the LLMs are faced with large and complex programming problems. A useful technique to improve the output of LLM-based programming assistants is to sample multiple answers or adapt the prompts iteratively.
| Source | LLM / Assistant | Capabilites |
| Denny et al. 2023 | GitHub Copilot | 💡 Copilot solved 50 % of 166 programming problems successfully on its very first attempt and 60 % of the remaining problems using only natural language changes to the problem description |
| Chen et al. 2021 | Codex | 💡 The Codex model is able to solve 28.8% of the problems in the HumanEval data set 💡 Repeated sampling is an effective strategy for producing working solutions to difficult prompts. When using 100 samples per problem, the performance of Codex jumps to being able to solve 70.2% of the problems. |
| Yetistiren et al. 2022 | GitHub Copilot | 💡 Copilot produces 28.7% fully correct, 51.2% partially correct, and 20.1% incorrect solutions for problems of the HumanEval data set 💡 The efficiency of the generated code was comparable to the time complexity of canonical solutions |
| Nguyen and Nadi 2022 | GitHub Copilot | 💡 Copilot solves LeetCode questions fully correct in 27% to 57% of cases, depending on the programming language. Additionally, Copilot produces partially correct solutions in an additional 27 % to 39 % of cases |
| Dakhel et al. 2022 | GitHub Copilot | 💡 Copilot was able to solve fundamental algorithmic problems such as sorting and implementing basic data structures. 💡 The correct ratio of human solutions was higher, but repairing the buggy solutions generated by Copilot required less effort |
Bug Fixing: Existing studies reveal that LLM-based assistants reproduce vulnerabilities at a rate comparable to human developers when generating code. This phenomenon likely stems from the fact that they are trained on public repositories and consequently mirror the characteristics of these repositories, including mixed code quality, in their responses. While LLMs perform well in detecting and fixing bugs in existing code, they are still outperformed by specialized tools.
| Source | LLM / Assistant | Capabilites |
| Pearce et al. 2021 | Codex | 💡 Codex has the ability to generate fixes for security bugs with carefully crafted prompts in a zero-shot setting, achieving a 100 % success rate in synthetic and hand-crafted scenarios 💡 It can fix an additional 58 % of historical bugs in open-source projects |
| Sobania et al. 2023 | ChatGPT | 💡 Regarding code security, ChatGPT vastly outperforms standard APR methods in its bug-fixing performance 💡 The conversational interface offers the possibility to provide feedback to the model and reiterate a solution, giving ChatGPT an overall success rate of 77.5% |
| Prenner and Robbes 2021 | Codex | 💡 When differentiating between different programming languages, Codex performs significantly better for Python than Java code when fixing bugs. 💡 Codex outperforms automatic program repair tools like CoCoNuTand DeepDebug in Python debugging tasks. However, the tool CURE outperforms Codex in Java debugging tasks |
| Asare et al. 2022 | GitHub Copilot | 💡 Copilot replicates vulnerable code approximately 33% of the time and replicates fixed code at a rate of 25% 💡 Thus, Copilot is not as prone as human developers to introducing vulnerabilities in code |
| Pearce et al. 2022 | GitHub Copilot | 💡 When being tested in 89 code-generating scenarios, Copilot produced solutions where approximately 40 % of them included vulnerabilities |
Code Testing: Although the assistants can assist in software testing, for instance by generating unit tests, they are not as effective as dedicated tools.
| Tufano et al. 2020 | GPT-3 | 💡 In the realm of generating unit tests, GPT-3 is outperformed by dedicated tools like EvoSuite. However, it still manages to produce correct unit tests for a third of the methods tested. 💡 The tests are readable and also occasionally achieve optimal coverage |
Impact of LLM-based assistants on developers
There is also a growing body of research that analyzes how programming assistants impact software developers when they are introduced into the software development process. Most studies indicate that LLM-based assistants have a positive effect on developers, often by allowing them to program faster. Autocomplete assistants like GitHub Copilot are perceived as beneficial due to their ability to provide suggestions quickly without disrupting the workflow. On the other hand, conversational interfaces like ChatGPT are appreciated as they allow developers to communicate flexibly and ask follow-up questions.
| Source | LLM programming assistant that was tested | Effect on the developers |
| Peng et al. 2023 | Github Copilot (autocomplete interface, context aware | 💡 Developers with GitHub Copilot completed the task 55.8 % faster than the control group 💡 In a self-assessment, the developers estimated a 35 % increase in productivity by using GitHub Copilot |
| Vaithilingam et al. 2022 | Github Copilot (autocomplete interface, context aware) | 💡 GitHub Copilot did not make developers faster since developers review code less and face debugging rabbit holes later 💡 Developers still preferred interacting with GitHub Copilot over interacting with IntelliSense |
| Mozannar et al. 2022 | Github Copilot (autocomplete interface, context aware) | 💡 More than half of the programming time was spend on Copilot related activities 💡 The largest fraction of time in a programming session was spend on double-checking and editing Copilot suggestions |
| Barke et al. 2022 | Github Copilot (autocomplete interface, context aware) | 💡 The communication between the developer and assistant happened in two modes 💡 In acceleration mode developers knew what to program and prefered small code-based suggestions 💡 In exploration mode developers conceptualized the solution and prefered abstract natural language prompts with larger scope |
| Jiang et al. 2022 | Self-made snippet generator that takes natural language prompts and generates HTML snippets (autocomplete interface, context blind) | 💡 Participants used AI assistants for quick API lookups and boilerplate code 💡 The scope of the prompts is mostly low granularity equivalent to a singe line of code 💡 Reiterations of prompts are popular to improve suggestions iteratively |
| Ross et al. 2023 | Self-made chatbot powered by react-chatbot-kit and the Codex model (conversational interface, context aware) | 💡 A chatbot allows for more flexible prompts like asking general programming questions, generate code snippets, asking follow up questions and reiterating the code 💡 Developers perceived that the conversational assistance aids their productivity |
| Sandoval et al. 2022 | Github Copilot (autocomplete interface, context aware) | 💡 LLM had a likely beneficial impact on functional correctness and does not increase the incidence rates of severe security bugs |
| Ziegler et al. 2022 | Github Copilot (autocomplete interface, context aware) | 💡 The acceptance rate of Copilot recommendations was a strong predictor of the perceived productivity |
| Qureshi 2023 | ChatGPT (conversational interface, context aware) | 💡 The group that utilized ChatGPT achieved higher scores in less time when solving programming problems 💡 ChatGPT required deep understanding of the tool and prompting skills to generate solutions for complex problems |
The goal of my study
Surprisingly, the studies in the previous literature only examine one specific type of LLM-based assistant at a time. What is missing in this body of research is a holistic approach that considers both types of programming assistants that emerged, autocomplete and conversational assistants, and additionally measures developer productivity in a comprehensive way using multiple dimensions.
Therefore, I designed a within-subjects study where software developers complete Phyton applications while working with three different programming environments. One environment serves as the control scenario and has no programming assistant installed. Another environment has GitHub Copilot installed, which represents autocomplete assistants. The third environment has an integrated version of ChatGPT installed, which serves as an example for conversational AI assistants.
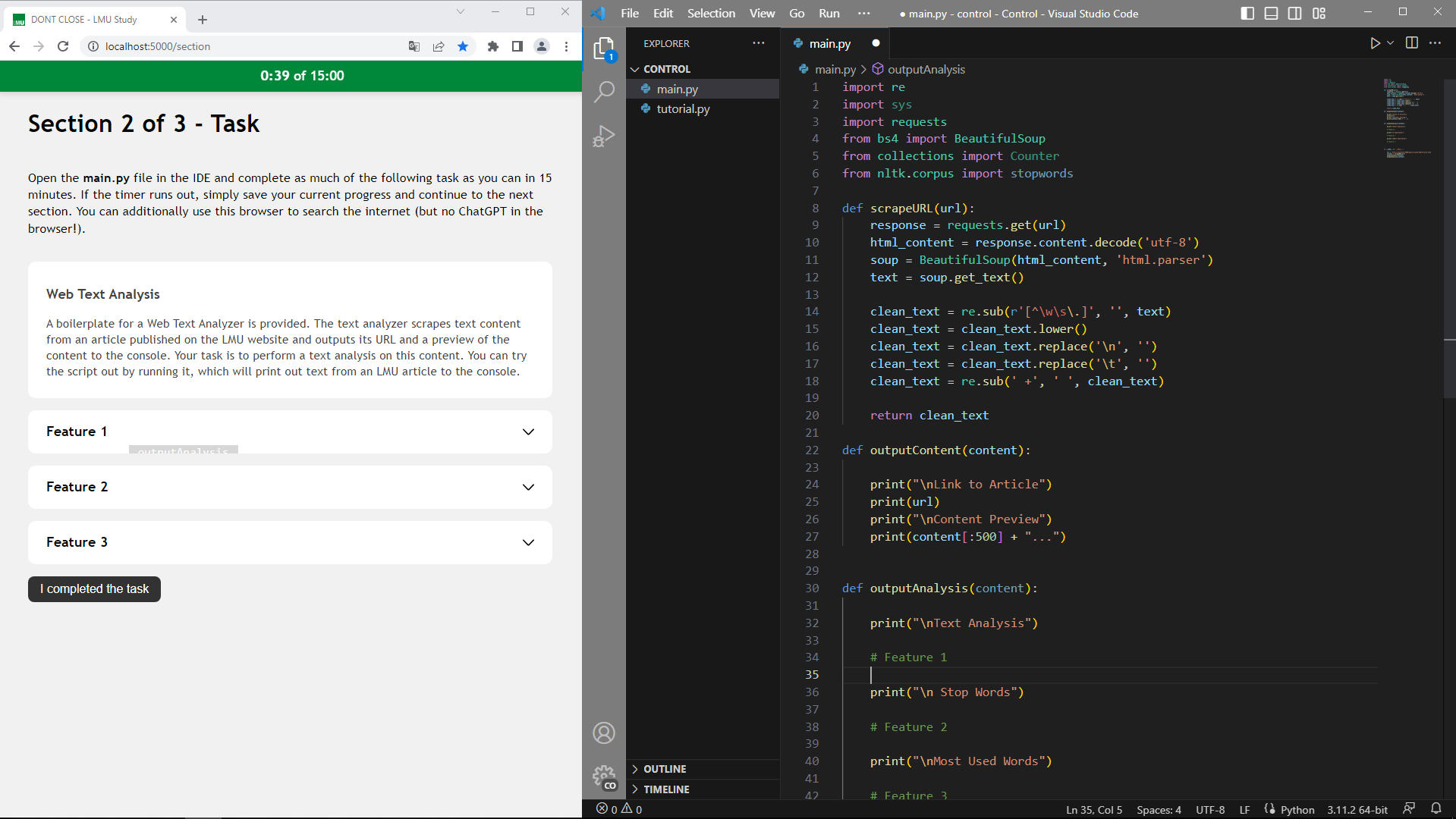

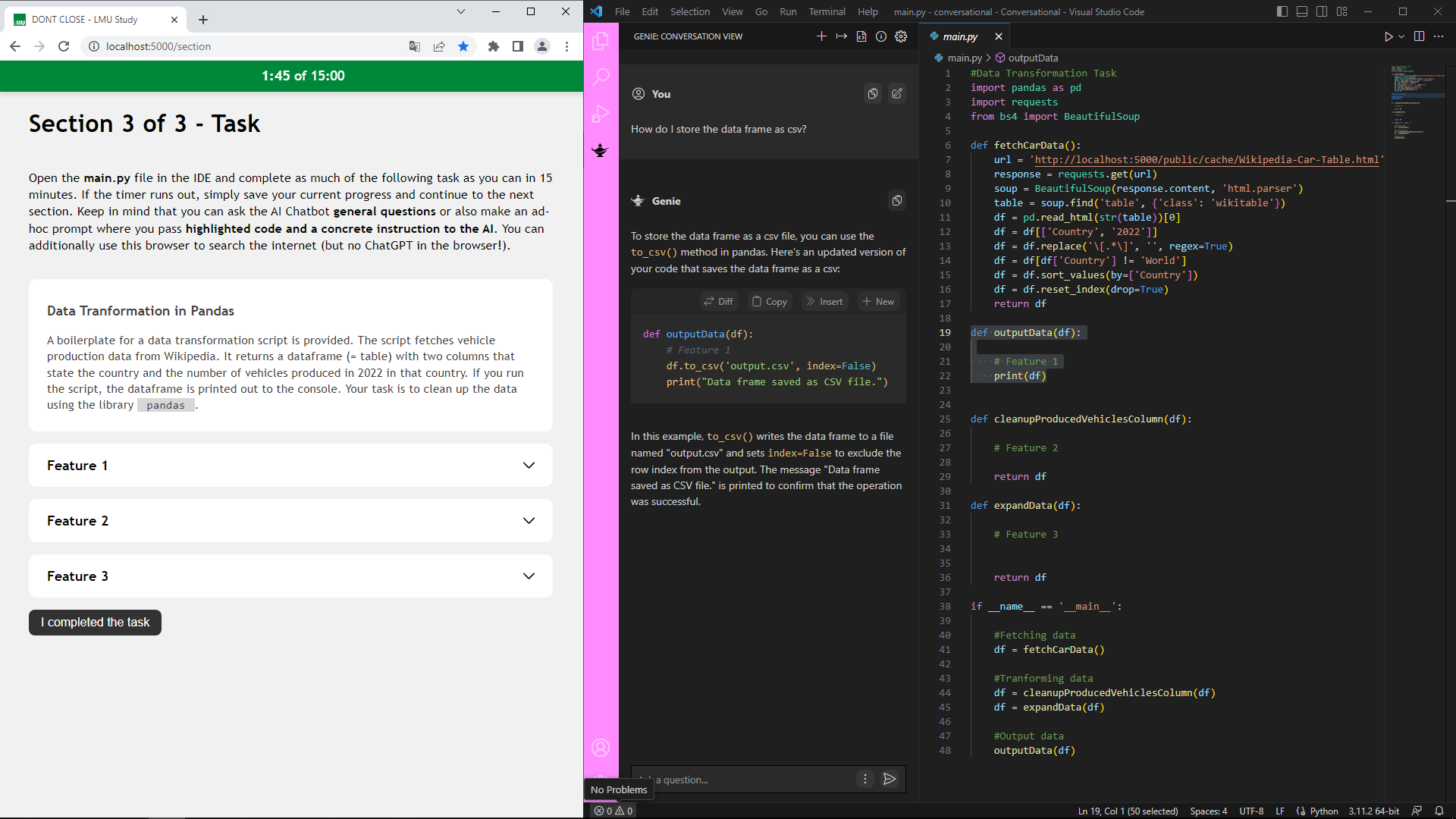
The experiment is conducted via a virtual machine, which is shown in the image above (click to enlarge). On the left side, the software developer gets instructions about features that should be added to a Python application. The code base of the application is opened in VSCode on the right. The developer’s job is to implement the requested features while leveraging the tools offered by the IDE.
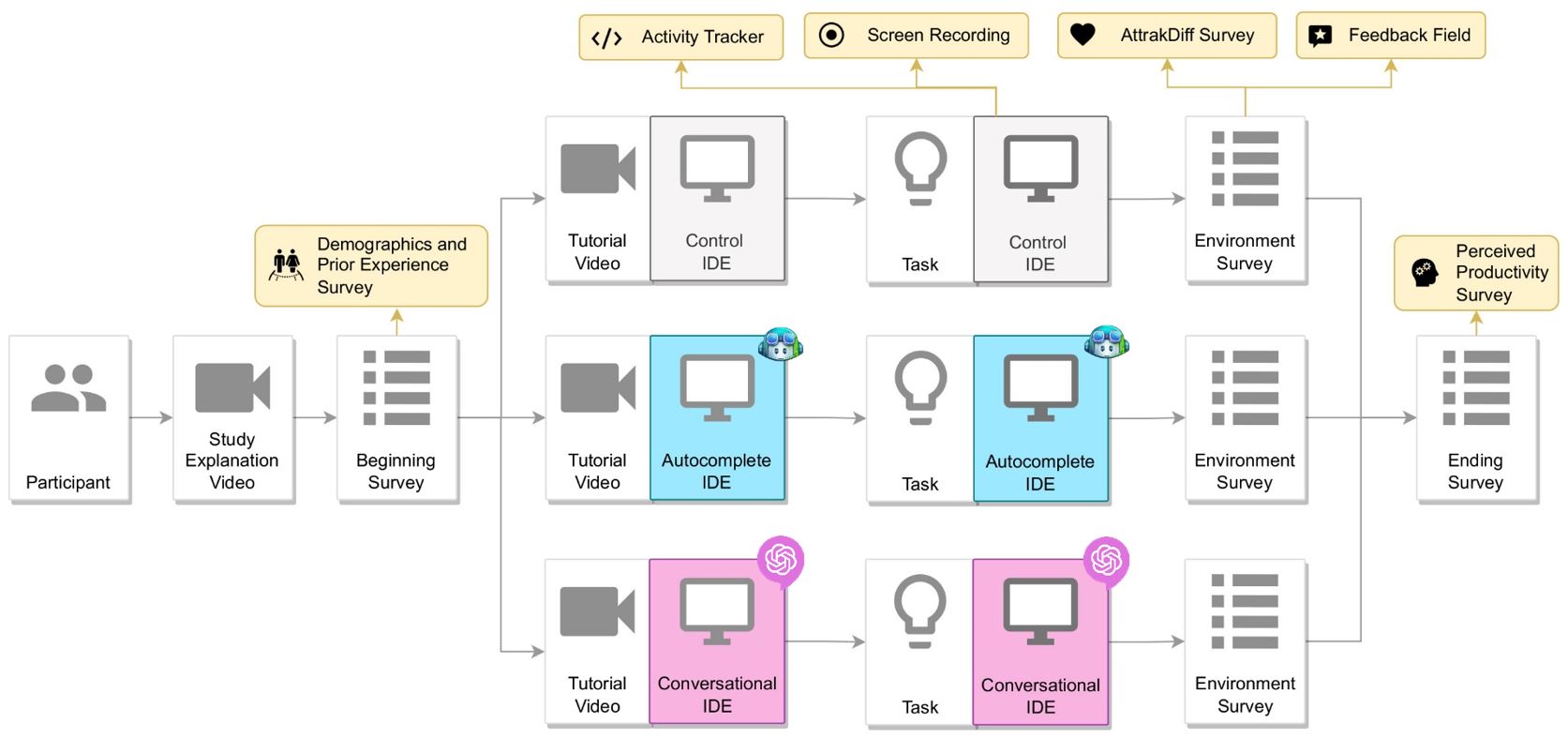
While the developers complete the tasks, the virtual machine tracks multiple productivity metrics which are categorized into five dimensions: Satisfaction, Performance, Communication, Activity, and Efficiency (Forsgren et al. 2021). An activity tracker was programmed specifically for this study to monitor the developers’ activity directly in the IDE. Additionally, self-assessment surveys are used to collect the subjective opinions of the developers, and the screen of the participants is recorded. This data collection leads to 16 productivity metrics in total, which provide an in-depth insight into the developers’ productivity.
Are you interested in contributing? (Closed)
Here is my invite to any developer or IT manager with a team that would like to try out the different AI assistants in the context of this study and in return receive a report of the findings:
Are you curious about how AI could shape your future as a developer? 💻 While I may not have the answer just yet, I'd like to extend a warm invitation for you to join an engaging study that I am currently conducting. My research explores how developers can benefit from using AI assistants to generate code. Here are a few key details: • 🎯 Topic: Solving Python programming tasks with AI assistants • 💰 Compensation: 12€ per hour plus MMI points if you are an LMU student • ⏳ Duration: The study takes approximately 1:15 h to complete • 🐍 Requirements: Being a developer with some Python experience • 🌍 Location: The study can be conducted remotely. I will check that everything runs smoothly over MS Teams and then you can complete the study using your own PC. Interested? Simply pick a timeslot here: [Study closed] While the study is of course scientifically sound, I promise that it is also quite fun since you get to play around with state-of-the-art AI assistants and explore their potential. Looking forward to embarking on this AI exploration journey with you! 🚀🌟



